После нахождения лица необходимо определить, в какую сторону оно повёрнуто, и привести его к общему виду для последующего анализа, ведь лицо, повёрнутое в разные стороны, это лицо одного и того же человека.
После определения точек необходимо изменить изображение так, чтобы глаза и рот были как можно лучше центрированы. Для таких преобразований используются аффинные преобразования, то есть такие преобразования, при которых все линии остаются параллельными вне зависимости от способа преобразования (искажение, поворот, масштабирование).
По итогам преобразования, вне зависимости от того, как повёрнуто лицо на исходном изображении, нейронная сеть получит на вход изображение с одинаковым положением основных частей лица человека.
Самый простой подход к распознаванию лица заключается в непосредственном сравнении неизвестного лица, со всеми изображениями людей, которые уже были отмечены ранее.
Если будет найдено ранее отмеченное лицо, которое очень похоже на распознаваемое лицо, то это наверняка один и тот же человек. Но у этого подхода есть большая проблема.
Сравнение всех отмеченных ранее лиц с каждым новым загруженным изображением занимает слишком много времени, в то время как лица должны распознаваться за миллисекунды, а не за часы.
Эффективным способом оптимизации сравнения является переход от сравнения всего изображения к сравнению отдельных измерений, например, размер ушей, расстояние между глазами и так далее.
Выбор частей необходимых для измерения можно возложить на нейронную сеть. Глубокое обучение, определяет, какие части лица нужно измерять, лучше, чем люди.
Решение заключается в создании сверточной нейронной сети глубокого обучения которая должна быть обучена создавать 128 измерений для каждого лица.
Во время обучения сети анализируется одновременно три лица: Обучающее изображение лица известного человека. Другая фотография того же известного человека.
Изображение совершенно другого человека. Алгоритм просматривает измерения, которые он делает для каждого из этих трех изображений.
Затем он немного настраивает нейронную сеть, чтобы удостовериться, что измерения, созданные для изображений 1 и 2, будут более похожи, а измерения для 2 и 3 — менее похожи.
Повторив этот этап миллионы раз для миллионов изображений тысяч разных людей, нейронная сеть учится надежно создавать 128 измерений для каждого человека.
Любые десять разных изображений одного и того же человека должны давать примерно одинаковые измерения. Полученные 128 измерений каждого лица называют картой.
Идея преобразования массива необработанных данных, например, изображения, в список генерируемых компьютером чисел крайне важна для машинного обучения.
Процесс обучения сверточной нейронной сети для получения карты лиц требует большого количества данных и мощного компьютера.
Последний этап заключается в поиске человека в базе данных, который ближе всего подходит под полученные 128 измерений исходного изображения.
Для поиска изображения необходимо обучить небольшую опорную сеть используя алгоритм классификации, например, метод опорных векторов.
Основная идея метода заключается в переводе исходных векторов в пространство более высокой размерности и поиск разделяющей гиперплоскости с наибольшим зазором в этом пространстве.
Две параллельных гиперплоскости строятся по обеим сторонам гиперплоскости, разделяющей классы. Разделяющей гиперплоскостью будет гиперплоскость, создающая наибольшее расстояние до двух параллельных гиперплоскостей.
Алгоритм основан на допущении, что чем больше разница или расстояние между этими параллельными гиперплоскостями, тем меньше будет средняя ошибка классификатора.
Проектируемая систем — система видеонаблюдения с возможностью распознавания лиц. Данная система представляет из себя мобильное и веб-приложение, которое позволяет в режиме реального времени осуществлять просмотр видеотрансляции из записывающего устройства.
Проектируемая система видеонаблюдения позволяет пользователям вести трансляцию из видеоустройства, выполнять распознавание лиц, отправлять уведомления при обнаружении движения, сохранять изображение при фиксации движения, а также обучать модель по средствам добавления новых лиц через пользовательский интерфейс.
Проектируемая система разделена на три группы актеров: «Видеокамера», «Пользователь», «Сервер». Каждая группа обладает определенным набором разрешенных действий.
«Видеокамера» обладает следующими возможностями:
- Обнаружение движения;
- Передача изображения на сервер;
- Трансляция видеопотока.
«Пользователь» обладает следующими возможностями:
- Войти в систему;
- Выйти из системы;
- Зарегистрироваться в системе;
- Удаление изображений в базе данных;
- Просмотр изображений из базы данных;
- Добавление записывающих устройств;
- Удаление записывающих устройств;
- Загрузка изображений для обучения системы.
«Сервер» обладает следующими возможностями:
- Обнаружение и распознавание лиц;
- Отправка сообщения в Telegram-бот;
- Изменение/просмотр базы данных; Обучение системы.
Но как только сеть будет обучена, она сможет генерировать измерения для любого лица, даже для встреченного впервые. Таким образом, все полученные изображения лиц необходимо пропустить через готовую обученную сеть, чтобы получить 128 измерений для каждого лица.
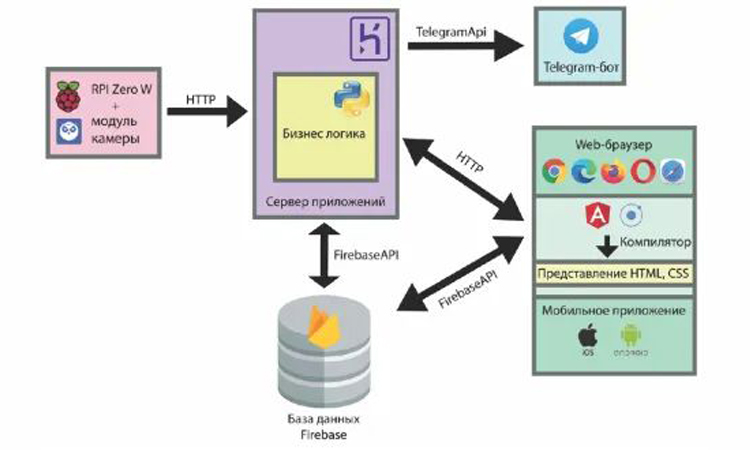
Проектируемая система состоит из четырех компонентов:
- Записывающее устройство;
- Серверная часть приложения;
- База данных;
- Пользовательский интерфейс.
Модуль «устройство видеонаблюдения» транслирует видеопоток в режиме реального времени. В случае, если на изображении обнаружено движение формируется HTTP запрос к серверной части приложения.
В серверной части на уровне контроллеров обрабатывается HTTP запрос, то есть выбирается нужная функция для работы с поступившим запросом.
Затем слой контроллеров вызывает необходимые функции на уровне сервисов. После этого слой сервисов вызывает соответствующие функции слоя данных. Слой данных делает запись в базу данных.
После чего отправляется сообщение в соответствующий телеграмм-бот. После взаимодействия пользователя с пользовательским интерфейсом системы, вызываются соответствующие функции в клиентской части приложения для обработки действия пользователя.
Затем клиентская часть приложения обращается к Firebase-API для взаимодействия с данными приложения. В качестве записывающего устройства используется одноплатный компьютер Raspberry Pi Zero W с модулем камеры.
На устройстве установлена операционная система MotioneyeOS. Разработка серверной части системы производится на языке программирования Python с использованием фреймворка Flask.
При разработке данной части приложения использовалась систему контроля версий Git, а также консоль Heroku для развертывания приложения.
Для удобства разработки рекомендуется использовать среду разработки программного обеспечения Visual Studio Code. Для развертывания документо-ориентированной базы данных используется Firebase Database.
Для хранения медиа-данных должна используется Firebase Storage. Для удобства работы с базой данных рекомендуется использовать Firebase Console.
В сущности user_account содержится информация о пользователе, а также массивы со списком устройств, используемых пользователем, а также списком команд выполняемых пользователем в процессе работы устройства.
Каждая из записей user_device_list содержит:
- Основную информацию (параметры и статус девайса);
- Данные о местоположении девайса; Массив со списком данных, получаемых из девайса;
- Массив, содержащий сообщения, отправленные пользователю из записывающего устройства.
Разработка клиентской части приложения выполнялась при помощи JavaScript-фреймворка Angular и Ionic. Также при разработке данной части приложения использовлся HTML5 и CSS, а также препроцессор CSS — SCSS.
Для удобства разработки рекомендуется использовать среду разработки программного обеспечения Visual Studio Code.
Пользовательский интерфейс состоит из четырех страниц:
- Страница регистрации;
- Страница онлайн трансляции;
- Страница скриншотов;
- Страница добавления новых лиц, для распознавания.
Авторы: Луцик Ю.А., Жуковец А.Н.