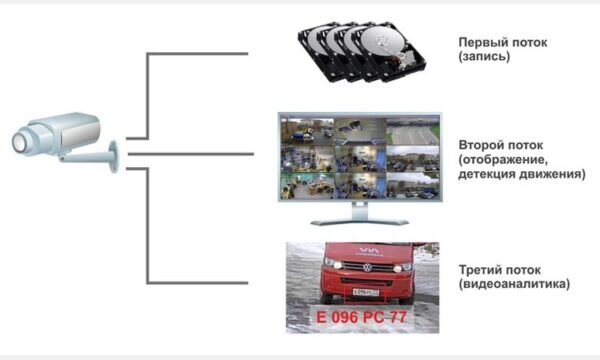
Видеоаналитика, используемая в работе систем видеонаблюдения, позволяет контролировать многие процессы, которые раньше контролировал человек. Слежение за определенными объектами, определение их параметров, внесение в базу данных и многое другое делается автоматически благодаря появлению видеоаналитики.
Сегодня в ее работе применяют искусственный интеллект, машинное и глубокое обучение. Но чем они отличаются, многие не знают. Постараемся убрать этот пробел.
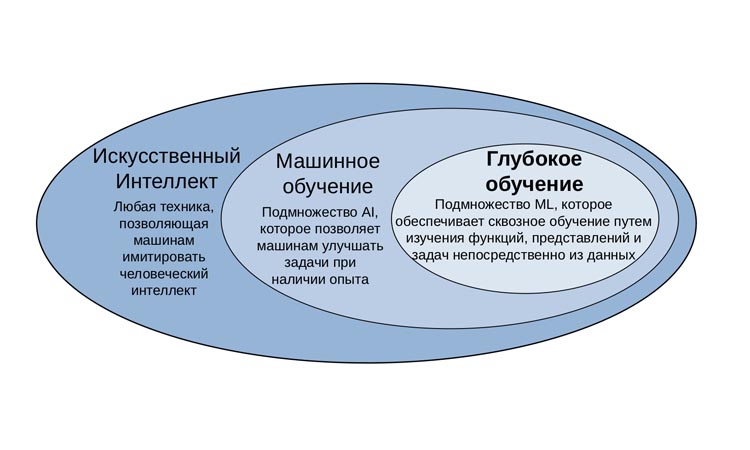
Искусственный интеллект или сокращенно ИИ — это метод, позволяющий компьютерам имитировать человеческий интеллект. Машинное обучение – это способ достижения искусственного интеллекта. Используя методы машинного обучения и глубокого обучения, можно создавать компьютерные системы и приложения, которые выполняют задачи, обычно связанные с человеческим интеллектом. Эти задачи включают распознавание изображений, распознавание речи и перевод языка.
Машинное обучение представляет собой подмножество искусственного интеллекта, который использует методы, которые позволяют машинам использовать опыт для улучшения выполняемых задач. Процесс машинного обучения основан на следующих принципах:
- Преобразование данных в алгоритм. На этом этапе можно предоставить дополнительную информацию модели, например, выполняя извлечение функций.
- Использование данных для обучения модели.
- Проверка и размещение модели.
- Использование полученной модели для выполнения автоматизированных задач прогнозирования. Другими словами, это вызов и использование полученной модели для получения прогнозов, возвращенных данной моделью.
В течение нескольких десятилетий машинное обучение использовалось как метод достижения искусственного интеллекта в машинах. По своей сути, область машинного обучения ориентирована на создание компьютеров, которые могут учиться и принимать решения, что делает машинное обучение хорошо подходящим для исследований в области искусственного интеллекта.
Однако не все модели машинного обучения предназначены для разработки искусственного интеллекта, который идеально соответствует или превосходит человеческий интеллект. Вместо этого модели часто предназначены для исследования конкретных, ограниченных проблем.
Глубокое обучение — это подмножество машинного обучения, основанное на искусственных нейронных сетях. Процесс обучения достаточно глубок, потому что структура искусственных нейронных сетей состоит из нескольких входных, выходных и скрытых слоев. Каждый слой содержит единицы, которые преобразуют входные данные в информацию, которую следующий слой может использовать для определенной задачи прогнозирования. Благодаря этой структуре машина может учиться с помощью собственной обработки данных. Данная технология положена в основу распознавания речи и распознавания объектов на изображениях. Видеонаблюдение нового поколения также использует соответствующие алгоритмы для идентификации людей или автомобильных номерных знаков с помощью системы видеоанализа.
Машинное обучение и глубокое обучение являются алгоритмическими. В классическом механическом обучении исследователи используют относительно небольшой объем данных и определяют, какие наиболее важные функции находятся в данных, которые необходимы алгоритму для прогнозирования. Этот метод называется особенностью. Например, если в программе обучения машин учат распознавать образ самолета, его программисты будут делать алгоритмы, которые позволят программе распознавать типичные формы, цвета и размеры коммерческих самолетов. С помощью этой информации программа машинного обучения сделает прогнозы относительно того, представлены ли изображения с включенными самолетами.
Глубокое обучение обычно отличается от классического машинного обучения его многочисленными уровнями принятия решений. Сети с глубоким обучением часто считаются «черными ящиками», поскольку данные анализируются через несколько сетевых уровней, каждый из которых делает наблюдения. Это может сделать результаты более трудными для понимания, чем результаты классического машинного обучения. Точное количество уровней или шагов в процессе принятия решений зависит от типа и сложности выбранной модели.
Машинное обучение традиционно использует небольшие наборы данных, из которых можно учиться и делать прогнозы. Имея небольшой объем данных, исследователи могут определить точные функции, которые помогут программе машинного обучения понять и извлечь уроки из данных.
Однако, если программа работает с информацией, которую она не может классифицировать на основе своих ранее существовавших алгоритмов, исследователям обычно необходимо вручную проанализировать проблемные данные и создать новую функцию. Из-за этого классическое машинное обучение обычно не очень хорошо масштабируется с огромным количеством данных, но оно может минимизировать ошибки в меньших наборах данных.
Традиционно машинное обучение имеет несколько общих и значительных ограничений. Overfitting — это статистическая проблема, которая может повлиять на алгоритм машинного обучения. Алгоритм машинного обучения содержит определенное количество «ошибок» при анализе и прогнозировании с данными.
Предполагается, что алгоритм должен показать взаимосвязь между соответствующими переменными, но при переопределении он также начинает фиксировать ошибку, что приводит к «более шумной» или неточной модели.
Модели машинного обучения также могут быть смещены в сторону особенностей данных, с которыми они были обучены, проблема, которая особенно очевидна, когда исследователи разрабатывают алгоритмы для всего доступного набора данных вместо того, чтобы сохранять часть данных для тестирования алгоритма.
Глубокое обучение особенно подходит для больших наборов данных, и для моделей часто требуются большие наборы данных. Из-за сложности сети глубокого обучения сеть нуждается в значительном объеме данных обучения и дополнительных данных для тестирования сети после обучения. В настоящее время исследователи перерабатывают сети глубокого обучения, которые могут быть более эффективными и использовать меньшие наборы данных.
Глубокое обучение весьма ресурсоемко. Разбор большого количества информации с помощью нескольких уровней принятия решений требует большой вычислительной мощности. По мере того, как компьютеры становятся быстрее, глубокое обучение становится все более доступным.
Глубокое обучение имеет те же статистические недостатки, что и классическое машинное обучение, а также несколько уникальных проблем. Для многих проблем недостаточно данных для обучения достаточно точной сети глубокого обучения. Это часто невозможно или невозможно собрать больше данных или имитировать проблему реального мира, которая ограничивает текущий диапазон тем, которые могут использоваться для глубокого обучения.
Подводя итог всему вышесказанному, отметим, что в видеоаналитике сегодня используется ИИ или так называемые нейронные сети. Они основаны на методах машинного обучения, которое включает в себя принцип глубокого обучения, хотя и не только его.
Машинное и глубокое обучение описывают методы обучения компьютерам для изучения и принятия решений с помощью псевдоискусственного интеллекта.
Надеемся, что те, кто использует видеоаналитику в работе системы видеонаблюдения теперь больше понимают основы ее функционирования.
(На картинке к статье отображена зависимость между ИИ, МО и ГО).